Wprowadzenie do programowania w języku Python¶
Wbudowane typy Pythona¶
Interpreter języka Python posiada następujące wbudowane typy danych:
Kategoria typu |
Nazwa typu |
Opis |
|---|---|---|
None |
Types.NoneType |
Obiekt None (obiekt null) |
Liczby |
bool |
True lub False (Boolean) |
int |
Liczba całkowita |
|
float |
Liczba zmiennoprzecinkowa |
|
complex |
Liczba zespolona |
|
Zbiory |
set |
Zbiór zmienny |
frozenset |
Zbiór niezmienny |
|
Sekwencje |
str |
Łańcuch znaków |
list |
Lista |
|
tuple |
Krotka |
|
bytes |
Ciąg bajtów |
|
Odwzorowania |
dict |
Słownik |
Pliki |
file |
Plik |
W języku Python zmienne nie posiadają typu – posiadają go wartości wskazywane przez zmienne.
Do sprawdzenia jakiego typu jest wartość wskazywana przez zmienną służy funkcja type():
>>> numbers = [1,2,3]
>>> type(numbers)
<type 'list'>
>>> type(numbers) == list
True
Podstawy składni Pythona¶
Komentarze¶
Komentarze w Pythonie są oznaczane za pomocą znaku hasza (#):
# Cała linia komentarza
x = 1 # Krótki komentarz: przypisz do zmiennej x wartość 1
Zmienne i przypisania¶
Ponieważ Python jest językiem z dynamiczną kontrolą typów, zmienne nie muszą mieć określonego typu w momencie deklaracji. Zmienna o określonej nazwie może wskazywać na obiekty różnych typów:
>>> var = 'text'
>>> var
'text'
>>> var = 1
>>> var
1
Usunięcie zmiennej jest dokonywane przy pomocy instrukcji del:
>>> del var
var
Traceback (most recent call last):
File "<console>", line 1, in <module>
NameError: name 'var' is not defined
Operatory¶
Operatory arytmetyczne¶
Składnia |
Opis |
|---|---|
|
Dodaje liczby x i y. |
|
Odejmuje liczbę y od x. |
|
Mnoży liczbę x przez y. |
|
Dzieli liczbę x przez y. Wynikiem jest liczba zmiennoprzecinkowa, nawet jeśli oba operandy są liczbami całkowitymi. |
|
Dzielenie z odrzuceniem części dziesiętnej. Wynikiem jest zawsze liczba całkowita int. |
|
Oblicza resztę z dzielenia (modulus) x przez y. |
|
Podnosi liczbę x do potęgi y. |
|
Zmienia znak liczby x, jeśli jest niezerowa. Jeśli x jest zerem, operator nic nie robi. |
>>> a, b, c = 5.0, 2.0, 1.0
>>> a / b
2.5
>>> a // b
2.0
>>> a % b
1.0
>>> a * b
10.0
Operatory skrócone: +=, -=, *=, /=, itp.
>>> a = 5
>>> a += 8
13
Operatory porównania¶
Składnia |
Opis |
|---|---|
|
Znak mniejszości |
|
Mniejszy lub równy |
|
Znak większości |
|
Większy lub równy |
|
Znak równości |
|
Różny od |
>>> a, b, c = 5.0, 2.0, 1.0
>>> a > b
True
>>> a == b
False
>>> a != b
True
Operatory logiczne¶
- Język Python udostępnia trzy operatory logiczne:
and – koniunkcja
or – alternatywa
not – negacja
>>> t = True
>>> f = False
>>> t2 = True
>>> t and f
False
>>> t and t2
True
>>> not f
True
Operatory bitowe¶
Składnia |
Opis |
|---|---|
|
Bitowe OR dla liczb int i oraz int j. Zakładamy, że liczby ujemne są przedstawiane wraz z uzupełnieniem dwójkowym. |
|
Bitowe XOR (LUB wyłączające) liczb i oraz j. |
|
Bitowe AND liczb i oraz j. |
|
Przesunięcie i w lewo o j bitów. |
|
Przesunięcie i w prawo o j bitów. |
|
Odwrócenie bitów i. |
Używanie wcięć kodu¶
Bloki kodu są oznaczane przez wcięcia wierszy. Liczba spacji we wcięciu może być różna, jednak wszystkie instrukcje wewnątrz bloku muszą być wcięte o tyle samo.
Oba bloki w pierwszym przykładzie są poprawne:
if True:
print("Prawda")
else:
print("Falsz")
Drugi blok w drugim przykładzie wygeneruje błąd:
if True:
print("Odpowiedz")
print("Prawda")
else:
print("Odpowiedz")
print("Falsz")
Łańcuchy znaków¶
Zwykłe łańcuchy znaków w Pythonie tworzone są poprzez ujęcie danego tekstu w apostrofy (') lub
cudzysłów ("). Ten sam znak ograniczający powinien rozpoczynać i kończyć łańcuch. Można także
użyć potrójnie cytowanego łańcucha znaków z użyciem trzech znaków cytowania – trzech
apostrofów (''') lub trzech cudzysłowów (""").
word = 'słowo'
sentence = "To jest zdanie."
paragraph = """To jest akapit. Składa się z kilku wierszy i zdań."""
Jeśli wewnątrz zwykłego łańcucha znaków ma zostać użyty inny łańcuch znaków, to należy ograniczyć każdy z łańcuchów za pomocą innych znaków. W przeciwnym wypadku konieczna będzie zmiana znaczenia znaków ograniczających.
sentence1 = "Używamy 'apostrofów', \"cudzysłów\" poprzedzamy ukośnikiem"
sentence2 = 'Znaki \'apostrof\' poprzedzamy ukośnikiem, a "cudzysłów" nie'
Formatowanie łańcuchów znaków¶
Łańcuchy znaków mogą być formatowane z użyciem predefiniowanego formatującego łańcucha znaków z listą zmiennych.
>>> letter = """Szanowny Panie %s, \n
... Dziękujemy za przesłanie nam pańskiego %s.\n
... Skontaktujemy się z Panem w %d roku."""
>>> print(letter % ("Kowalski", "CV", 2010))
Szanowny Panie Kowalski,
Dziękujemy za przesłanie nam pańskiego CV.
Skontaktujemy się z Panem w 2010 roku.
>>> record = "%s | %s | %s | %08d"
>>> print(record % ("Guido", "van Rossum", "Dutch", 1956))
Guido | van Rossum | Dutch | 00001956
Format specyfikatora konwersji:
%[(klucz słownika)][flaga konwersji][min. szerokość][precyzja] [typ konwersji]
Flaga konwersji |
Znaczenie |
|---|---|
|
Uzupełnienie zerami szerokości pola |
|
Justowanie do lewej |
|
Wstawienie spacji przed dodatnią liczbą |
|
Wstawienie znaku przed liczbą |
Typ konwersji |
Znaczenie |
|---|---|
|
string lub unicode |
|
Liczba całkowita |
|
Liczba zmiennoprzecinkowa |
|
Liczba zmiennoprzecinkowa w formacie wykładniczym |
|
Liczba w formacie szesnastkowym |
|
Liczba w formacie ósemkowym |
Przykład
>>> "%+10.3f" % (3.14)
' +3.140'
>>> "%x" % 255
'ff'
- format(*args, **kwargs)¶
W Pythonie 3.0 operator
%został zastąpiony znacznie potężniejszą metodą formatowania łańcuchów,format(). Wsparcie dlastr.format()zostało przeportowane do Pythona 2.6. Zarówno łańcuchy znaków 8-bitowe, jak i Unicode, mają teraz metodęformat(), która traktuje łańcuch jako wzorzec i pobiera argumenty do jego sformatowania. Wzorzec zawiera nawiasy klamrowe{}jako znaki specjalne.
>>> # Podstaw argument o numerze 0
>>> "User ID: {0}".format("root")
'User ID: root'
>>> # Użyj argumentów nazwanych
>>> "ID: {id} Last seen: {login}".format(id="root", login="5/03/2022")
'ID: root Last seen: 5/03/20222'
Warunkowe wykonanie kodu¶
Instrukcja if, else oraz elif¶
if x:
print("x jest prawdą")
elif y:
print("x jest fałszem, a y jest prawdą")
else:
print("oba są fałszem")
Wszystkie wartości w Pythonie mogą być reprezentowane przez wartości logiczne, niezależnie od ich typu.
Wyrażenie przyjmuje wartość False, jeżeli jest predefiniowaną stałą False, obiektem specjalnym None, pustą sekwencją, kolekcją (na przykład, pusty łańcuch znaków, lista lub krotka) lub liczbowym typem danych o wartości 0.
Wszystko pozostałe jest uznawane za True.
>>> bool(-1.23)
True
>>> bool(0)
False
>>> bool([])
False
>>> bool([0, 0, 0])
True
Klauzula else jest opcjonalna.
Wyrażenie warunkowe¶
Zapis z wykorzystaniem instrukcji warunkowej if/else
if condition:
x = true_value
else:
x = false_value
może być skrócony przy pomocy wyrażenia warunkowego
x = true_value if condition else false_value
Przykład
>>> var = None
>>> print([] if var is None else var)
[]
>>> var = [1, 2, 3]
>>> print([] if var is None else var)
[1, 2, 3]
Pętle¶
Instrukcja while¶
Pętla warunkowa.
ans = input('>>> ')
while ans != 'q':
print(ans)
ans = input('>>> ')
>>> text
text
>>> q
Instrukcja for¶
Pętla operująca na sekwencjach.
for zmienna in iteracja:
pakiet
Do części zmienna zostaje po kolei przypisane odniesienie do każdego obiektu w części iteracja. Wymieniona iteracja to dowolny typ danych, przez który można przejść, między innymi ciągi tekstowe, listy, krotki oraz inne kolekcje typów danych Pythona.
Przykład 1 - wykorzystanie łańcucha znaków
>>> word = "Python"
>>> characters = []
>>> for character in word:
... characters.append(character)
...
>>> characters
['P', 'y', 't', 'h', 'o', 'n']
Przykład 2 - wykorzystanie funkcji range()
>>> for i in range(len(characters)):
... print(i, characters[i])
...
0 P
1 y
2 t
3 h
4 o
5 n
Przykład 3 – wykorzystanie funkcji enumerate(string)
>>> for i, character in enumerate(string):
... print(i, character)
...
0 P
1 y
2 t
3 h
4 o
5 n
Przykład 4 – wykorzystanie słownika
>>> d = {'one': 1, 'two': 2}
>>> for key in d:
... print(key, '=', d[key])
...
one = 1
two = 2
Przykład 5. Wykorzystanie funkcji zip(), która z dwóch lub więcej sekwencji tworzy listę krotek
>>> first_names = ['John', 'Alice']
>>> family_names = ['Smith', 'Johnson']
>>> list(zip(first_names, family_names))
[('John', 'Smith'), ('Alice', 'Johnson')]
>>> # Lista wykorzystana w pętli for
>>> for first_name, family_name in zip(first_names, family_names):
... print(first_name, family_name)
...
John Smith
Alice Johnson
Instrukcje break i continue¶
breakprzerwanie wykonywania i wyjście z bieżącej pętli
continueprzerwanie wykonywania bieżącej iteracji i rozpoczęcie kolejnej iteracji bieżącej pętli
while True:
ans = input('>>> ')
if ans == 'q':
break
elif ans == '':
continue
else:
print(eval(ans))
>>>
>>> 2 + 2
4
>>> q
Instrukcja for-else¶
W języku Python można użyć instrukcji else w pętli for.
Blok występujący po else wykona się jeśli wewnątrz pętli for nie wystąpiła instrukcja break.
Czyli kod
broke_out = False
for x in seq:
do_something(x)
if condition(x):
broke_out = True
break
do_something_else(x)
if not broke_out:
print("I didn't break out")
można zastąpić kodem
for x in seq:
do_something(x)
if condition(x):
break
do_something_else(x)
else:
print("I didn't break out")
Na przykład
>>> numbers = [2, 3, 4]
>>> for number in numbers:
... if number < 0:
... print('Znaleziono ujemną liczbę:', number)
... break
... else:
... print('Nie znaleziono ujemnej liczby.')
...
Nie znaleziono ujemnej liczby.
Obsługa błędów¶
Jeśli w trakcie działania programu wystąpi zgłoszenie nieobsłużonego wyjątku, Python zatrzyma wykonywanie programu i wyświetli informacje o ostatnich wywołaniach.
>>> 10 * (1/0)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ZeroDivisionError: integer division or modulo by zero
>>> 4 + spam*3
Traceback (most recent call last):
File "<stdin>", line 1, in ?
NameError: name 'spam' is not defined
>>> '2' + 2
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: cannot concatenate 'str' and 'int' objects
Informacje o ostatnich wywołaniach (backtraces) powinny być odczytywane od ostatniego wiersza do pierwszego. W ostatnim wierszu podany jest nieobsłużony wyjątek, który został zgłoszony. Powyżej znajduje się nazwa pliku, numer wiersza, nazwa funkcji oraz wiersz, który spowodował zgłoszenie wyjątku.
Obsługa błędów jest wykonywana poprzez wykorzystanie wyjątków, które są ujmowane w bloki try i obsługiwane w blokach except.
Jeśli napotykany jest błąd, wykonywanie kodu z bloku try jest zatrzymywane i przenoszone do bloku except.
>>> while True:
... try:
... x = int(input("Please enter a number: "))
... break
... except ValueError as error:
... print("Oops!", error, "Try again...")
Wartość typu wyjątku odnosi się albo do wyjątków wbudowanych albo do samodzielnie zdefiniowanego obiektu wyjątku.
Wartość error jest zmienną, która przechwytuje dane zwracane przez wyjątek.
Blok try obsługuje także wykorzystywanie bloku else po ostatnim bloku except.
Blok else jest wykonywany, jeśli blok try zakończy działanie bez otrzymania wyjątku.
>>> try:
... f = open("plik.txt", 'r')
... except IOError as error:
... print(error)
... else:
... print('plik.txt has', len(f.readlines()), 'lines')
... f.close()
Blok except może obsługiwać wiele typów wyjątków:
... except (RuntimeError, TypeError, NameError):
... pass
Podstawowe typy błędów¶
Typ |
Opis |
|---|---|
|
Klasa bazowa dla wszystkich klas opisujących błędy |
|
Próba użycia nieistniejącego klucza w słowniku |
|
Wyszukiwanie w liście nieistniejącej wartości |
|
Wywołanie nieistniejącej metody obiektu |
|
Użycie nieistniejącej zmiennej |
|
Mieszanie niezgodnych typów danych |
|
Błąd operacji we/wy |
|
Błąd dzielenia przez zero |
|
Błąd składni |
|
Odwołanie do nieistniejącego indeksu sekwencji |
Zgłaszanie wyjątków¶
Wyjątki mogą być zgłaszane przy pomocy instrukcji raise.
>>> raise NameError('HiThere')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
NameError: HiThere
Blok finally służy do sprzątania zasobów, gdy zgłoszona zostanie sytuacja wyjątkowa.
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Clean-up!')
Clean-up!
KeyboardInterrupt
Traceback (most recent call last):
File "<stdin>", line 2, in ?
Pełna składnia obsługi wyjątków¶
try:
wykonaj_to_dzialanie()
except OneExceptionType:
wykonaj_jesli_rzucono_OneExceptionType()
except AnotherExceptionType as ex:
wykonaj_jesli_rzucono_AnotherExceptionType(ex)
else:
wykonaj_jesli_brak_wyjatku()
finally:
zawsze_wykonaj()
Funkcje¶
Definicja i użycie funkcji
def reminder(a, b):
"""Zwraca reszte z dzielenia a/b"""
q = a // b
r = a - q*b
return r
>>> # Użycie funkcji
>>> a = reminder(42, 5) # a = 2
>>> print (a)
2
>>> print (reminder.__doc__)
Zwraca resztę z dzielenia a/b
Funkcje mogą zwracać wiele wartości. Wartości zwracane pakowane są do krotki.
def divide(a, b):
q = a/b
r = a - q*b
return q, r
x, y = divide(42,5) # x = 8, y = 2
Definiowanie parametrów funkcji i sposoby wywoływania:
def generate_signature(name, location, year=2009):
print("{} / {} / {}".format(name, location, year))
>>> generate_signature("Robert", "Kraków")
Robert / Kraków / 2009
>>> generate_signature(location="Berlin", year=2004, name="Anna")
Anna / Berlin / 2004
>>> generate_signature("Artur", year=2005, location="Toronto")
Artur / Toronto / 2005
- Parametry mogą być przekazywane również jako:
Krotka – przy pomocy składni z *
Słownik – przy pomocy składni z **
>>> tuple = ("Edward", "Kolonia", 2003)
>>> generate_signature(*tuple)
Edward/Kolonia/2003
>>> dictionary = {"name": "Zenon", "location": "Gdynia", "year": 1999}
>>> generate_signature(**dictionary)
Zenon/Gdynia/1999
Operator lambda¶
Operator lambda umożliwia tworzenie funkcji anonimowych.
Składnia: lambda <args> : <expression>
>>> bigger = lambda a, b : a > b
>>> bigger(1, 2)
False
>>> bigger(2, 1)
True
Kolekcje¶
Typy sekwencyjne¶
Typy sekwencyjne w Pythonie są iterowalne.
Obiekty można przeglądać element po elemencie (np. w pętli for).
Sekwencje umożliwiają również dostęp do dowolnego elementu za pomocą operacji indeksowania [].
- Podstawowymi typami sekwencyjnymi są:
str,unicodelisttuple
Lista¶
- Lista (
list) uporządkowany zbiór obiektów
Lista może dynamicznie rosnąć, by obsługiwać dodawanie nowych obiektów
Listy mogą przechowywać obiekty różnych typów
Elementy listy są dostępne za pomocą indeksu rozpoczynającego się od zera i będącego nieujemną liczbą całkowitą
Definiowanie listy¶
Definiowanie listy w Pythonie odbywa się poprzez przypisanie pewnej liczby obiektów Pythona do zmiennej za pomocą operatora =.
Lista musi być zawarta w nawiasach kwadratowych i może zawierać dowolny wybór obiektów Pythona.
Możliwe jest tworzenie zarówno list homogenicznych jak i heterogenicznych.
Lista pusta jest definiowana jako [].
Przykład:
empty_list = [] # Lista pusta
num_list = [2018, 2019, 2020, 2021]
string_list = ["Ważny", "kod", "Pythona"]
mixed_list = [1, 2, "trzy", 4]
sub_list = ["Python", "InfoTraining", ["Szkolenie", 2017]]
list_list = [num_list, string_list, mixed_list, sub_list]
for x in list_list:
for y in x:
if isinstance(y, int):
print(y + 1)
if isinstance(y, str):
print("Łańcuch znaków: " + y)
2019
2020
2021
2022
Łańcuch znaków: Ważny
Łańcuch znaków: kod
Łańcuch znaków: Pythona
2
3
Łańcuch znaków: trzy
5
Łańcuch znaków: Python
Łańcuch znaków: InfoTraining
Dostęp do listy¶
Dostęp do elementów listy odbywa się za pomocą indeksu rozpoczynającego się od zera. Python pozwala na wykorzystanie indeksów ujemnych w dostępie do listy od końca zamiast od początku. Jeśli element listy także jest listą, dostęp do jej elementów odbywa się poprzez dodanie na końcu nawiasów indeksujących, w sposób podobny do dostępu do elementów wielowymiarowej tablicy.
# Wszystkie elementy
for x in num_list:
print(x+1)
# Niektóre elementy
print(string_list[0] + ' ' + string_list[1] + ' ' + string_list[2])
# Indeksy ujemne
print(string_list[-2])
# Dostęp do elementów z podlist
if isinstance(sub_list, list):
print(sub_list[2][0])
2001
2004
2006
2007
Ważny kod Pythona
kod
Wydano
Długość listy¶
- len(sequence)¶
Ilość elementów przechowywanych w liście jest zwracana przy pomocy funkcji wbudowanej
len.
>>> num_list = [2000, 2003, 2005, 2006]
>>> len(num_list)
4
>>> empty_list = []
>>> len(empty_list)
0
Dodawanie i usuwanie elementów listy¶
- append(item)¶
metoda ta przyjmuje pojedynczy element item jako jedyny parametr i dodaje go na końcu listy. Elementem może być dowolny obiekt Pythona, także inna lista. Jeśli określi się listę jako parametr, lista dodawana jest w całości jako pojedynczy element bieżącej listy.
- extend(list)¶
jednoczesne dodawanie kilku elementów przechowywanych w innej liście list. Metoda ta jako argument przyjmuje tylko listę. Każdy element nowej listy zostanie dodany jako osobny element do starej listy.
>>> numbers = ["Trzy"]
>>> numbers.append("Cztery")
>>> numbers.extend(["Pięć", "Sześć"])
>>> numbers
['Trzy', 'Cztery', 'Pięć', 'Sześć']
Można także dodać jedną bądź więcej list do istniejącej listy za pomocą operatora +=.
numbers += ['Siedem', 'Osiem']
- insert(index, item)¶
metoda przyjmuje jako swój drugi parametr pojedynczy obiekt item i wstawia go do listy pod indeksem index określonym w pierwszym argumencie.
- pop(index)¶
metoda usuwa element o indeksie index.
- remove(item)¶
metoda przeszukuje listę i usuwa pierwszy odnaleziony element item.
>>> numbers.insert(2, "Dwa i 1/2")
>>> print(numbers.pop(2))
Dwa i 1/2
>>> numbers.remove("Pięć")
>>> numbers.remove("Sześć")
>>> numbers
['Trzy', 'Cztery', 'Siedem', 'Osiem']
Sortowanie listy¶
- sort(key=None, reverse=False)¶
metoda sortująca elementy listy wg wartości (in-place). Metoda
sortmoże przyjmować argument o nazwiekeybędący funkcją. Funkcja ta powinna przyjmować jeden argument, który będzie używany do stworzenia klucza dla każdego obiektu listy. Klucz ten będzie wykorzystywany do sortowania listy w miejsce wartości tych samych obiektów.
Sortowanie w odwrotnej kolejności jest możliwe z użyciem słowa kluczowego reverse jako argumentu metody sort:
reverse jest typu
Booleanustawione na
True- lista sortowana w odwrotnej kolejnościsłowo kluczowe
reversemoże być używane wraz z funkcjami porównania lub klucza
- reverse()¶
metoda używana do odwrócenia kolejności elementów listy bez ich sortowania.
names.reverse()
names.sort(reverse=1)
Przykład:
>>> names = ["ala", "Ola", "Zenon", "Artur", "beata", "Grzegorz"]
>>> names
['ala', 'Ola', 'Zenon', 'Artur', 'beata', 'Grzegorz']
Sortowanie z uwzględnieniem wielkości liter:
>>> names.sort()
>>> names
['ala', 'Ola', 'Zenon', 'Artur', 'beata', 'Grzegorz']
Sortowanie bez uwzględnienia wielkości liter:
>>> names.sort(key=str.upper)
>>> names
['ala', 'Artur', 'beata', 'Grzegorz', 'Ola', 'Zenon']
Sortowanie malejące według dlugości imion:
>>> names.sort(reverse=True, key=len)
>>> names
['Grzegorz', 'Artur', 'beata', 'Zenon', 'ala', 'Ola']
Odwrócenie kolejności:
>>> names.reverse()
>>> names
['Ola', 'ala', 'Zenon', 'beata', 'Artur', 'Grzegorz']
Pozostałe metody listy¶
- count(value)¶
Zwraca ilość wystąpień danej wartości w liście
- index(value)¶
Zwraca indeks danej wartości w liście. Jeżeli wartość nie znajduje się w liście, zgłaszany jest wyjątek
ValueError
- insert(pos, value)¶
Wstawia do listy wartość
valueprzed element o indeksiepos.
Wycinek listy¶
Wycinek (slice) - podzbiór listy
Wycinek otrzymuje się poprzez odwołanie do listy i określenie dwóch rozdzielonych przecinkiem indeksów, które odnoszą się do elementów znajdujących się pomiędzy indeksami, a nie do jednego indeksu
Pierwsza liczba odnosi się do elementu listy, od którego należy rozpocząć, a druga - element, na którym należy zakończyć
firstHalf = monthList[:halfCount]
secondHalf = monthList[halfCount:]
wordCount = len(firstHalf)
middleStart = wordCount//2
middleHalf = monthList[middleStart:middleStart+halfCount]
Wycinki zwracane są jako typy listy i dostęp do nich oraz przypisanie odbywają się w analogiczny sposób. Python umożliwia wykorzystanie indeksów ujemnych w celu indeksowania od końca w momencie wyodrębniania wycinków.
Przykład:
monthList = ["styczeń", "luty", "marzec",\
"kwiecień", "maj", "czerwiec", "lipiec", \
"sierpień", "wrzesień", "październik",\
"listopad", "grudzień"]
wordCount = len(monthList)
halfCount = wordCount//2
# Wycinek początkowy
firstHalf = monthList[ : halfCount]
print(firstHalf)
# Wycinek końcowy
secondHalf = monthList[halfCount : ]
print(secondHalf)
# Wycinek środkowy
wordCount = len(firstHalf)
middleStart = wordCount//2
middleHalf = monthList[middleStart : \
middleStart+halfCount]
print(middleHalf)
# Indeksy ujemne
print(monthList[-5:-1])
# Co n-ty element listy
print(monthList[0:12:3])
['styczeń', 'luty', 'marzec', 'kwiecień', 'maj', 'czerwiec']
['lipiec', 'sierpień', 'wrzesień', 'październik', 'listopad', 'grudzień']
['kwiecień', 'maj', 'czerwiec', 'lipiec', 'sierpień', 'wrzesień']
['sierpień', 'wrzesień', 'październik', 'listopad']
Operator in¶
Na typach sekwencyjnych (lista, krotka, string, itp.) można wykonywać działania z wykorzystaniem
operatora przynależności do zbioru in lub not in.
>>> monthList = ["styczeń", "luty", "marzec", "kwiecień", "maj", "czerwiec"]
>>> "luty" in monthList
True
>>> "lipiec" not in monthList
True
Krotka¶
Krotka (tuple)
Uporządkowany zbiór obiektów oparty na indeksach
Wersja listy tylko do odczytu
hexStringChars = ('A', 'B','C', 'D', 'E', 'F')
hexStringNums = ('1', '2', '3', '4', '5', '6', '7', '8', '9', '0')
Krotka a lista¶
Krotka jest niezmienna (immutable). Elementy nie mogą być do niej dodawane ani z niej usuwane. Dane w niej zawarte pozostaną statyczne.
Krotka jest definiowana podobnie jak lista, ale umieszczana w nawiasach zwykłych, a nie kwadratowych.
Krotka jest szybsza od listy pod względem dostępu i użycia.
Krotka może być używana jako klucz dla słowników, a lista - nie.
list(tuple)- funkcja konwertująca krotkę na listę.tuple(list)- funkcja konwertująca listę na krotkę.
Wykorzystywanie krotek¶
Przykład:
hexStringChars = ('A', 'B','C', 'D', 'E', 'F')
hexStringNums = ('1', '2', '3', '4', '5', '6', '7', '8', '9', '0')
hexStrings = ["1FC", "1FG", "222", "Dziesięć"]
for hexString in hexStrings:
for x in hexString:
if ((not x in hexStringChars) and (not x in hexStringNums)):
print(hexString + " nie jest szesnastkowym łańcuchem znaków.")
break
# Zamiana krotki na listę
tupleList = list(hexStringChars)
print(tupleList)
# Zamiana listy na krotkę
listTuple = tuple(hexStrings)
print(listTuple)
1FG nie jest szesnastkowym łańcuchem znaków.
Dziesięć nie jest szesnastkowym łańcuchem znaków.
['A', 'B','C', 'D', 'E', 'F']
("1FC", "1FG", "222", "Dziesięć")
Słownik¶
Słownik (dictionary) - nieuporządkowany zbiór par obiektów
Para składa się z obiektu klucza oraz obiektu wartości
Klucz jest używany do odszukiwania wartości drugiego obiektu
Słownik zachowuje się podobnie do tablicy mieszającej (hash table)
Dostęp do słownika może się odbywać za pomocą metod indeksujących
Tworzenie słownika¶
Tworzenie słownika odbywa się poprzez przypisanie grupy wartości wraz z odpowiadającymi im kluczami do zmiennej. Wartościami mogą być dowolne obiekty Pythona. Klucze muszą być liczbą, łańcuchem znaków lub niezmienną krotką (tuple).
>>> numberDict = {1: 'raz', 2: 'dwa', 3: 'trzy', 4: 'cztery'}
>>> numberDict[1]
'raz'
>>> numberDict[3]
'trzy'
Relacje w słownikach¶
Proste słowniki składają się z relacji „jeden do jednego” pomiędzy kluczami a wartościami.
Relację „jeden do wielu” można uzyskać poprzez wykorzystanie obiektów listy jako wartości w słowniku.
Relację „wiele do wielu” otrzymuje się używając krotek jako kluczy i list jako wartości w słowniku.
Przykład
# Słownik - relacja 1-1
numberDict = {1:'raz', 2:'dwa', 3:'trzy', 4:'cztery'}
# Słownik - relacja 1-N
phoneBook = { 'Artur' : ['22-222-21-12', '606-32-23-11'],
'Roger' : ['22-111-22-22', '502-455-44-44', '888-122-44-44'] }
# Słownik - relacja N-M
numbers = (1,2,3,4,5,6,7,8,9,0)
letters = ('a','b','c','d','e','f')
punct = ('.', '!', '?')
charSetDict = { numbers : [], letters : [], punct : [] }
Dodawanie wartości do słownika¶
Aby dodać wartość do słownika należy ustanowić klucz, który będzie odpowiadać pewnej wartości.
Jeśli wybrany klucz nie istnieje jeszcze w słowniku, to zostanie do niego dodany, a następnie przypisana zostanie do niego wartość.
Jeśli klucz już istnieje, wartość obecnie do niego przypisana zostanie zastąpiona nowym obiektem wartości.
Typ obiektu wartości i klucza nie muszą sobie odpowiadać i w dowolnym momencie można zastąpić wartość nowym obiektem dowolnego typu.
Wielkość liter w kluczach słownika ma znaczenie.
Przykład:
>>> phonebook = {'jack': 4098, 'sape': 4139}
>>> phonebook['guido'] = 4127
>>> phonebook
{'sape': 4139, 'guido': 4127, 'jack': 4098}
>>> phonebook['jack'] = 4098
>>> del phonebook['sape']
>>> phonebook['irv'] = 4127
>>> phonebook
{'guido': 4127, 'irv': 4127, 'jack': 4098}
>>> phonebook.keys()
['guido', 'irv', 'jack']
>>> 'guido' in phonebook
True
Pobieranie wartości ze słownika¶
Bezpośredni dostęp do wartości za pomocą powiązanego z nią klucza w nawiasach kwadratowych [] następujących po zmiennej słownika.
- get(key[, d=None])¶
zwraca wartość skojarzoną z kluczem. Jeśli klucz nie istnieje zwraca d.
- values()¶
zwraca listę obiektów, które są wartościami słownika.
- keys()¶
zwraca listę obiektów, które są używane jako klucze.
- items()¶
metoda zwraca listę zawierającą dwuelementowe krotki dla każdej pary klucza i wartości ze słownika.
>>> phonebook = {'sape': 4139, 'guido': 4127, 'jack': 4098}
>>> phonebook.get('john', 'unknown')
'unknown'
>>> phonebook.values()
[4139, 4098, 4127]
>>> phonebook.keys()
['sape', 'jack', 'guido']
>>> phonebook.items()
[('sape', 4139), ('jack', 4098), ('guido', 4127)]
Pozostałe metody¶
- clear()¶
Usuwa wszystkie wpisy ze słownika
- copy()¶
Zwraca płytką kopię słownika
- fromkeys([key1, key2, ...])¶
Tworzy nowy słownik z kluczami wymienionymi na liście przekazanej jako argument. Wartości są ustawione na
None
- pop(key)¶
Odczytuje wartość skojarzoną z kluczem key a następnie usuwa wpis ze słownika
- setdefault(key, default)¶
Wstawia wartość do słownika, o ile nie istnieje w nim wpis o podanym kluczu
Iteracja po słownikach¶
- items()¶
W trakcie iteracji po słowniku pary klucz-wartość mogą być dostępne przy pomocy metody
items()
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
Wycinek słownika¶
Używamy metody .keys() do otrzymania listy kluczy i tworzymy z listy kluczy podzbiór listy przez wycinanie lub inne operacje.
Jeśli posiadamy konkretny podzbiór kluczy słownika. możemy pobrać wartości z oryginalnego słownika i dodać je do nowego słownika.
Przykład:
year = {1:'styczeń', 2:'luty', 3:'marzec', 4:'kwiecień',\
5:'maj', 6:'czerwiec', 7:'lipiec', 8:'sierpień',\
9:'wrzesień', 10:'październik', 11:'listopad',\
12:'grudzień'}
print(year)
# Otrzymanie listy kluczy
months = year.keys()
# Utworzenie podzbioru kluczy
months = list(months)
months.sort()
halfCount = len(months)//2
half = months[0:halfCount]
# Utworzenie nowego słownika z podzbioru kluczy
firstHalf = {}
for x in half:
firstHalf[x] = year[x]
print(firstHalf)
{1: 'styczeń', 2: 'luty', 3: 'marzec', 4: 'kwiecień', 5: 'maj',
6: 'czerwiec', 7: 'lipiec', 8: 'sierpień', 9: 'wrzesień', 10: 'październik',
11: 'listopad', 12: 'grudzień'}
{1: 'styczeń', 2: 'luty', 3: 'marzec', 4: 'kwiecień', 5: 'maj',
6: 'czerwiec'}
Zamiana kluczy na wartości w słowniku¶
Aby zamienić w słowniku klucze z wartościami, należy dokonać iteracji przez elementy słownika za pomocą metody items, a następnie wykorzystać wartości jako klucze przypisując im oryginalne klucze w charakterze wartości.
Wartości muszą być typami, które mogą być w Pythonie kluczami.
Przykład:
myDictionary = {
'kolor':'niebieski',
'prędkość':'szybka',
'liczba':1,
5:'liczba',
}
print(myDictionary)
# Zamiana kluczy z wartościami
swapDictionary = {}
for key, val in myDictionary.items():
swapDictionary[val] = key
print(swapDictionary)
{'kolor': 'niebieski', 'prędkość': 'szybka', 'liczba': 1, 5: 'liczba'}
{'niebieski': 'kolor', 1: 'liczba', 'liczba': 5, 'szybka': 'prędkość'}
Operacje na ciągach znaków¶
Łańcuchy znaków w Pythonie reprezentowane są z użyciem niezmiennego typu danych str, który
przechowuje sekwencję znaków.
Typ danych str można wywołać jako funkcję w celu utworzenia obiektu łańcucha znaków: * Wywołanie bez argumentu powoduje zwrócenie pustego łańcucha znaków. * Wywołanie z argumentem innym niż łańcuch znaków powoduje zwrócenie argumentu w formie łańcucha znaków. * Wywołanie z argumentem w postaci łańcucha znaków powoduje zwrócenie kopii danego łańcucha.
Porównywanie łańcuchów znaków¶
Łańcuchy znaków można porównywać ze sobą z użyciem prostych operacji logicznych <, <=, ==, !=, > oraz >=.
Operatory powodują porównywanie łańcuchów tekstowych w pamięci, bajt po bajcie.
cmpStr = "abc"
upperStr = "ABC"
if cmpStr.upper() == upperStr.upper():
print(upperStr + " odpowiada " + cmpStr)
Metody przydatne w trakcie porównywania:
- upper()¶
zwraca nowy łańcuch znaków, który składa się z wielkich liter
- lower()¶
zwraca nowy łańcuch złożony z małych liter
- capitalize()¶
zwraca nowy łańcuch, w którym pierwszy znak jest z wielkiej litery
- swapcase()¶
zwraca nowy łańcuch, w którym wielkość liter jest odwrócona
Przykład:
cmpStr = "abc"
upperStr = "ABC"
lowerStr = "abc"
print("Porównanie z uwzględnieniem wielkości liter")
if cmpStr == lowerStr:
print(lowerStr + " odpowiada " + cmpStr)
if cmpStr == upperStr:
print(upperStr + " odpowiada " + cmpStr)
print("\nPorównanie bez uwzględnienia wielkości liter")
if cmpStr.upper() == lowerStr.upper():
print(lowerStr + " odpowiada " + cmpStr)
if cmpStr.upper() == upperStr.upper():
print(upperStr + " odpowiada " + cmpStr)
Porównanie z uwzględnieniem wielkości liter
abc odpowiada abc
Porównanie bez uwzględnienia wielkości liter
abc odpowiada abc
ABC odpowiada abc
Segmentowanie i poruszanie się krokami w łańcuchu znaków¶
Poszczególne elementy sekwencji, a tym samym poszczególne znaki łańcucha tekstowego mogą być wyodrębnione za pomocą operatora dostępu ([]).
Operator ten może być wykorzystywany do wyodrębnienia nie tylko pojedynczego elementu lub znaku, ale również całego segmentu (podsekwencji) elementów lub znaków. W takim kontekście operator staje się operatorem segmentowania.
Wyodrębnianie poszczególnych znaków¶
Indeks w łańcuchu znaków rozpoczyna się od zera i osiąga wartość długości łańcucha minus jeden. Możliwe jest także używanie ujemnej wartości indeksu, która wskazuje pozycję obliczaną od ostatniego znaku w kierunku pierwszego. Indeks -1 zawsze wskazuje ostatni znak w łańcuchu.
Przykład: wartości pozycji indeksu w łańcuchu znaków:
s = "Python"
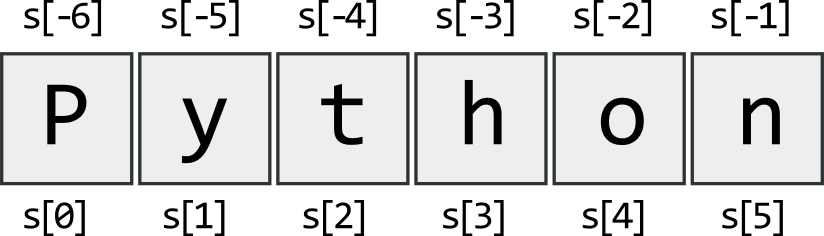
Przypisanie indeksu o wartości wykraczającej poza łańcuch znaków lub każdego indeksu w pustym łańcuchu powoduje zgłoszenie wyjątku IndexError.
Segmenty ciągu tekstowego¶
Operator segmentowania ma trzy składnie:
sekwencja[początek]sekwencja[początek:koniec]sekwencja[początek:koniec:krok]
Sekwencja oznacza dowolną sekwencję znaków, na przykład listę, łańcuch tekstowy lub krotkę. Wartości początek, koniec i krok muszą być liczbami całkowitymi lub zmiennymi przechowującymi liczby całkowite. Pierwsza składnia wyodrębnia element początkowy z sekwencji. Druga składnia powoduje wyodrębnienie segmentu rozpoczynającego się w miejscu początek o długości do miejsca koniec, ale bez tego elementu.
Jeśli pominięto pierwszy indeks, przyjmowana jest jego wartość domyślna czyli 0.
W przypadku pominięcia drugiego indeksu wartością domyślną jest wynik wywołania funkcji len(sekwencja).
Pominięcie obydwu indeksów spowoduje wyodrębnienie (skopiowanie) całej sekwencji. Wywołanie
s[:]odpowiada wywołanius[0:len(s)]
Przykład:

Trzecia składnia powoduje pobieranie znaków co wskazany krok.
Pominięcie indeksu początek powoduje przyjęcie jego wartości domyślnej (0 dla dodatniej wartości krok, - 1 dla ujemnej wartości krok).
W przypadku pominięcia drugiego indeksu wartością domyślną jest wynik wywołania funkcji
len(sekwencja), o ile wartość krok nie jest ujemna. Wówczas wartość domyślna indeksu koniec będzie znajdowała się przed początkiem łańcucha znaków.Jeśli zostaną pominięte obydwa indeksów oraz wartość krok, to zostanie przyjęta domyślna wartość krok czyli 1.
Niedozwolone jest stosowanie kroku o wartości 0.
Przykład:

W przykładzie użyto wartości domyślnych dla indeksów początek i koniec.
Polecenie s[::-2] oznacza rozpoczęcie działania od ostatniego znaku i wyodrębnienie co drugiego znaku, poruszając się w kierunku początku łańcucha znaków.
Polecenie s[::3] oznacza rozpoczęcie od pierwszego znaku i wyodrębnienie co trzeciego, poruszając się w kierunku końca łańcucha znaków.
Możliwe jest także połączenie segmentowania i poruszania się krokami.

Aby odwrócić łańcuch znaków, używamy kroku -1. Pozwala to wyodrębnić każdy znak od końca do
początku łańcucha znaków.
text = "The waxwork man"
print(text[::-1])
nam krowxaw ehT
Łączenie łańcuchów znaków¶
Jednym ze sposobów wstawiania podłańcucha znaków do istniejącego łańcucha jest połączenie segmentowania z konkatenacją.
text = "The waxwork man"
text = text[:12] + "wo" + text[12:]
print(text)
The waxwork woman
Ponieważ segment „wo” znajduje się w początkowym łańcuchu znaków, ten sam efekt można uzyskać poprzez użycie przypisania:
text = text[:12] + text[7:9] + text[12:]
print(text)
Stosowanie operatora + w celu konkatenacji i operatora += w celu dołączania nie jest efektywną metodą, zwłaszcza dla operacji na wielu łańcuchach znaków. Najlepszym rozwiązaniem będzie użycie metody str.join().
Formatowanie łańcuchów¶
Formatowanie łańcuchów razem jest wykonywane poprzez zdefiniowanie nowego łańcucha z kodem formatu %s, a następnie dodanie dodatkowych łańcuchów jako parametrów do wypełnienia każdego kodu formatu.
Metoda join(wordList)¶
Metoda join(wordList) zapewnia efektywny sposób łączenia wszystkich łańcuchów z listy. Każdy łańcuch jest po kolei dodawany do istniejącego łańcucha. Wykonuje operację string=+list[x] na każdej iteracji przez listę łańcuchów znaków. Łańcuch dodawany jako prefiks do każdego z elementów listy.
Przykład:
word1 = "Tylko"
word2 = "kilka"
word3 = "miłych"
word4 = "słów"
wordList = ["Tylko", "kilka", "więcej", "miłych", "słów"]
# Proste łączenie za pomocą metody join
print("Słowa:" + word1 + word2 + word3 + word4)
print("Lista: " + ' '.join(wordList))
# Sformatowany łańcuch znaków
sentence = ("Pierwsze zdanie: %s %s %s %s." % (word1,word2,word3,word4))
print(sentence)
# Połączenie listy słów
sentence = "Drugie zdanie:"
for word in wordList:
sentence += " " + word
sentence += "."
print(sentence)
Słowa:Tylkokilkamiłychsłów
Lista: Tylko kilka więcej miłych słów
Pierwsze zdanie: Tylko kilka miłych słów.
Drugie zdanie: Tylko kilka więcej miłych słów.
Dzielenie łańcuchów znaków¶
- split(separator)¶
metoda przeszukuje łańcuch znaków, dzieli go przy każdym wystąpieniu znaku separatora, a następnie rozkłada na listę łańcuchów znaków.
- splitlines(keeplineends)¶
metoda dzieli łańcuch na każdym znaku nowej linii na listę łańcuchów przyjmując jeden argument będący wartością logiczną
TruelubFalsew celu ustalenia, czy znak nowej linii powinien być zachowany.
Przykład:
sentence = "To jest proste zdanie."
paragraph = "To jest prosty akapit.\n\
Składa się on z wielu\n\
wierszy tekstu."
entry = "Imię i nazwisko:Artur Borucki:Zawód:Bramkarz"
print(sentence.split())
print(entry.split(':'))
print(paragraph.splitlines(1))
['To', 'jest', 'proste', 'zdanie.']
['Imię i nazwisko', 'Artur Borucki', 'Zawód', 'Bramkarz']
['To jest prost akapit.\n,
'Składa się on z wielu \n',
'linii tekstu.']
Wyszukiwanie podłańcuchów w łańcuchu¶
- find(sub[, start[, end]])¶
jeśli metoda nie odnajdzie podłańcucha znaków, zwracane jest -1
- index(sub[, start[, end]])¶
jeśli metoda nie odnajdzie podłańcucha, generowany jest wyjątek
subszukany podłańcuch znaków
start, endopcjonalne indeksy przeszukiwanego łańcucha
Przykład:
searchStr = "Czerwony Niebieski Fioletowy Zielony Niebieski Żółty Czarny"
searchStr.find("Czerwony")
searchStr.rfind("Niebieski")
searchStr.find("Niebieski")
searchStr.find("Turkusowy")
searchStr.index("Niebieski")
searchStr.index("Niebieski",20)
searchStr.rindex("Niebieski")
searchStr.rindex("Niebieski",1,18)
# Dane wyjściowe:
0
37
9
-1
9
37
37
9
Wyszukiwanie i zastępowanie w łańcuchach¶
- replace(old, new[, maxreplace])¶
zastępuje konkretny podłańcuch znaków nowym tekstem. Metoda przyjmuje poszukiwany łańcuch znaków jako pierwszy argument (old), a zastępujący łańcuch znaków jako drugi (new). Opcjonalnie można określić maksymalną liczbę zastąpień w trzecim argumencie maxreplace.
Przykład:
question = "Jaka jest prędkość lotu jaskółki bez obciążenia?"
print(question)
question2 = question.replace("jaskółki", "europejskiej jaskółki")
print(question2)
question3 = question.replace("jaskółki", "afrykańskiej jaskółki")
print(question3)
Jaka jest prędkość lotu jaskółki bez obciążenia?
Jaka jest prędkość lotu europejskiej jaskółki bez obciążenia?
Jaka jest prędkość lotu afrykańskiej jaskółki bez obciążenia?
Wyszukiwanie łańcuchów z prefiksem lub sufiksem¶
- startswith(prefix[, start[, end]])¶
sprawdza, czy łańcuch rozpoczyna się od właściwego prefiksu
- endswith(suffix[, start[, end]])¶
sprawdza, czy łańcuch kończy się właściwym sufiksem
Metody użyteczne do przetwarzania list plików w oparciu o rozszerzenia lub nazwy plików
prefix, suffixłańcuch znaków wykorzystywany do porównywania z prefiksem lub sufiksem łańcucha
start, endargumenty indeksujące
Przykład:
import os
for f in os.listdir('C:\\txtfiles'):
if f.endswith('.py'):
print("Plik Pythona: " + f)
elif f.endswith('.txt'):
print("Plik tekstowy: " + f)
Plik Pythona: comp_str.py
Plik Pythona: join_str.py
Plik tekstowy: output.txt
Plik Pythona: split_str.py
Przycinanie łańcuchów znaków¶
- strip([chrs])¶
usuwa określone znaki z obu stron łańcucha
- lstrip([chrs])¶
usuwa tylko znaki z początku łańcucha
- rstrip([chrs])¶
usuwa tylko znaki z końca łańcucha
Przykład:
import string
bad_sentence = "\t\tTo zdanie ma pewne problemy. "
bad_paragraph = "\t\tTen akapit \nma jeszcze więcej \nproblemów.!? "
# Odcięcie końcowych znaków spacji
print("Długość = " + str(len(bad_sentence)))
print("Bez końcowych spacji = " + \
str(len(bad_sentence.rstrip(' '))))
# Odcięcie znaków tabulatora
print("\nŹle:\n" + bad_sentence)
print("\nDobrze:\n" + bad_sentence.lstrip('\t'))
# Odcięcie znaków końcowych i początkowych
print("\nŹle:\n" + bad_paragraph)
print("\nDobrze:\n" + bad_paragraph.strip((' ?!\t')))
Długość = 33
Bez końców spacji = 30
Źle:
To zdanie ma pewne problemy.
Dobrze:
To zdanie ma pewne problemy.
Źle:
Ten akapit
ma jeszcze więcej
problemów.!?
Dobrze:
Ten akapit
ma jeszcze więcej
problemów.
Wyrównywanie i formatowanie łańcuchów¶
- rjust(width[, fill])¶
wyrównanie tekstu w łańcuchu o odpowiednią liczbę znaków do prawa
- ljust(width[, fill])¶
wyrównanie tekstu w łańcuchu o odpowiednią liczbę znaków do lewa
fillargument opcjonalny, wypełniający przestrzeń utworzoną przez wyrównanie podanym znakiem
%operator służący do przekazania argumentów do formatującego łańcucha znaków
Przykład:
chapters = {1:5, 2:46, 3:52, 4:87, 5:90}
hexStr = "3f8"
# Wyrównanie do prawej
print("Szesnastkowy łańcuch znaków: " + hexStr.upper().rjust(8,'0'))
print("")
for x in chapters:
print("Rozdział " + str(x) + \
str(chapters[x]).rjust(15,'.'))
# Wyrównanie do lewej
print("\nSzesnastkowy łańcuch znaków: " + hexStr.upper().ljust(8,'0'))
# Formatujący łańcuch znaków
for x in chapters:
print("Rozdział %d %15s" % (x, str(chapters[x])))
Szesnastkowy łańcuch znaków: 000003F8
Rozdział 1.............5
Rozdział 2............46
Rozdział 3............52
Rozdział 4............87
Rozdział 5............90
Szesnastkowy łańcuch znaków: 3F800000
Rozdział 1 5
Rozdział 2 46
Rozdział 3 52
Rozdział 4 87
Rozdział 5 90
Wykonywanie kodu zawartego w łańcuchach¶
- exec(str[, globals[, locals]])¶
funkcja wykonuje kod zawarty w łańcuchu znaków i zwraca jego wynik
- eval(str[, globals[, locals]])¶
funkcja analizuje łańcuch znaków jako wyrażenie Pythona oraz zwraca wyniki
code = "for card in cards: \
print('Karta = ' + card)"
exec(codeStr)
Zmienne lokalne locals oraz globalne globals są dodawane do środowiska wykorzystywanego dla wykonania kodu poprzez określenie globalnych lub lokalnych słowników, zawierających odpowiadające im nazwy i wartości zmiennych.
Przykład:
cards = ['As', 'Król', 'Królowa', 'Walet']
codeStr = "for card in cards: \
print(\"Karta = \" + card )"
areaStr = "pi*(radius*radius)"
# Wykonanie łańcucha znaków
exec(codeStr)
# Obliczenie łańcucha znaków
print("\nPole = " + str(eval(areaStr, {"pi":3.14}, {"radius":5})))
Karta = As
Karta = Król
Karta = Królowa
Karta = Walet
Pole = 78.5
Wyrażenia listowe i słownikowe¶
Wyrażenia listowe¶
Wyrażenia listowe (list comprehensions) pozwalają w zwięzły sposób odwzorować listę na inną, wykonując na każdym jej elemencie pewne operacje.
Pozwalają otrzymywać przekształcone listy bez odwoływania się do funkcji map i filter:
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [fruit.strip() for fruit in freshfruit]
['banana', 'loganberry', 'passion fruit']
>>> vec = [2, 4, 6]
>>> [3*x for x in vec]
[6, 12, 18]
>>> [3*x for x in vec if x > 3]
[12, 18]
>>> [3*x for x in vec if x < 2]
[]
Jeśli wynikiem wyrażenia ma być krotka, wyrażenie musi zostać ujęte w nawiasy ():
>>> [[x,x**2] for x in vec]
[[2, 4], [4, 16], [6, 36]]
>>> [x, x**2 for x in vec] # error - parens required for tuples
File "<stdin>", line 1, in ? [x, x**2 for x in vec] ^
SyntaxError: invalid syntax
>>> [(x, x**2) for x in vec]
[(2, 4), (4, 16), (6, 36)]
Wyrażenia listowe mogą działać na wielu listach:
>>> vec1 = [2, 4, 6]
>>> vec2 = [4, 3, -9]
>>> [x*y for x in vec1 for y in vec2]
[8, 6, -18, 16, 12, -36, 24, 18, -54]
>>> [x+y for x in vec1 for y in vec2]
[6, 5, -7, 8, 7, -5, 10, 9, -3]
>>> [vec1[i]*vec2[i] for i in range(len(vec1))]
[8, 12, -54]
Zagnieżdżone wyrażenia listowe¶
Wyrażenia listowe mogą być zagnieżdżone.
Przykład: macierz 3x3:
>>> mat = [
... [1, 2, 3],
... [4, 5, 6],
... [7, 8, 9],
... ]
Zamiana wierszy z kolumnami:
>>> print [[row[i] for row in mat] for i in [0, 1, 2]] [[1, 4, 7], [2, 5, 8],
[3, 6, 9]]
Odpowiednik przy użyciu iteracji:
for i in [0, 1, 2]:
for row in mat:
print(row[i], end='')
print("")
Wyrażenia słownikowe¶
Wyrażenia słownikowe (dictionary comprehension) pozwalają w zwięzły sposób stworzyć nowy słownik, w sposób podobny do wyrażeń listowych:
>>> pracownicy = [
... {'id': 15, 'name': 'Jan Kowalski'},
... {'id': 16, 'name': 'Janusz Nowak'},
... ]
>>> print({pracownik['id']: pracownik['name'] for pracownik in pracownicy})
{16: 'Janusz Nowak', 15: 'Jan Kowalski'}
Warto zauważyć, że zarówno w przypadku wyrażeń listowych, jak i słownikowych, można odwzorować kolekcję innego typu. W powyższym przykładzie przekształcono listę w słownik.
Funkcja map¶
Mapowanie polega na pobraniu funkcji oraz obiektu pozwalającego na iterację i wygenerowanie nowego obiektu iterowanego (lub listy), w którym każdy element będzie wynikiem wywołania funkcji względem odpowiadającego mu elementu w początkowym obiekcie pozwalającym na iterację.
- map(function, sequence)¶
wywołuje
function(item)dla każdego elementu sekwencji sequence i zwraca iterator po elementach wynikowych.
>>> def cube(x):
... return x*x*x
...
>>> list(map(cube, range(1, 11)))
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]
Funkcji map może być przekazana więcej niż jedna sekwencja. Funkcja przetwarzająca musi wówczas przyjmować dwa argumenty. Jeśli któraś z sekwencji jest krótsza, odpowiedni argument funkcji otrzyma wartość None.:
>>> numbers = range(8)
>>> def add(x, y): return x+y
...
>>> list(map(add, numbers, numbers))
[0, 2, 4, 6, 8, 10, 12, 14]
Funkcja filter¶
Filtrowanie obejmuje pobranie funkcji oraz obiektu pozwalającego na iterację i wygenerowanie nowego iteratora, w którym każdy element pochodzi z początkowego iteratora pod warunkiem, że funkcja wywołana względem tego elementu zwróciła wartość True.
- filter(function, sequence)¶
zwraca sekwencję tych elementów sekwencji przekazanej jako argument, które spełniają predykat
function.
>>> def condition(x): return x % 2 != 0 and x % 3 != 0
...
>>> list(filter(condition, range(2, 25)))
[5, 7, 11, 13, 17, 19, 23]
Operator lambda¶
Funkcje map i filter mogą korzystać z funkcji anonimowych definiowanych operatorem lambda.:
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(map(lambda x: x * x, numbers))
[1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> list(filter(lambda x: x%2 == 0, numbers))
[2, 4, 6, 8]
>>> reduce(lambda x,y: x+y, numbers)
45